The Physics vs. Feelings of AI: Architecting Autonomous Systems That Actually Scale
When it comes to scaling high-ticket revenue and managing daily operations, there’s one rule that dictates survival: physics vs. feelings.
You can feel like a new strategy is going to work, and you can buy into pitch decks promising that artificial intelligence is months away from running your entire company autonomously. But feelings don’t scale. Physics does. The current reality of AI systems tells a grittier, more demanding story than the marketing copy suggests.
We are entering the era of agentic workflows—where tools like Gemini, Claude, and specialized frameworks act as semi-autonomous workers. If you want to integrate these tools into your revenue operations without burning cash or trust, you must understand the structural limits of what they can do and how to engineer around those limits.
This is the real operational physics of AI agents—and the playbook for actually getting them to drive your business outcomes.
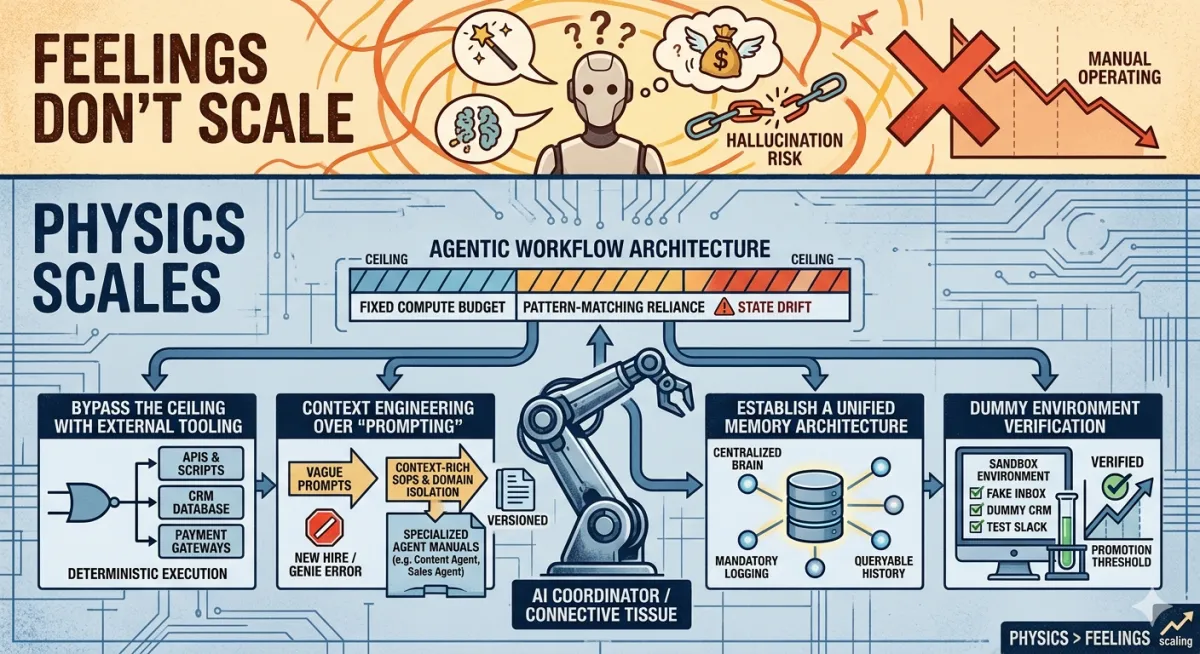
The Architecture of the Ceiling
Recent theoretical work on large language models shows that they operate under a fixed compute budget per generated token or step. They don’t “think harder” when a problem is difficult; they follow the same underlying architecture and inference process each time.
When a task demands more precise reasoning or longer chains of logic than the model can reliably represent in that budget, the system falls back to pattern-matching. It produces outputs that sound confident but may be logically wrong or factually fabricated. These “hallucinations” aren’t random glitches; they are a predictable consequence of how the models work.
The industry tried to patch this with “chain-of-thought” prompting and agentic loops—giving AI more steps to reason or letting it call itself in a loop. In practice, simply giving a pattern-matching engine more steps doesn’t turn it into a true reasoning engine. Over long, unconstrained runs, small errors compound, state drifts, and eventually the chain degrades, hallucinates, or breaks the process you were trying to automate.
The takeaway: there is an architectural ceiling on how much end-to-end autonomy you can safely delegate to a single, unconstrained AI agent.
The Orchestration Playbook: How to Build Agents That Actually Work
If you treat AI as an all-knowing operator, it will eventually fail you. If you treat it as an orchestrator inside a well-designed system, it becomes an unfair advantage.
Elite operators who are already driving millions with these tools don’t ask the AI to “run the business.” They design systems where:
Humans define the goals, constraints, and success metrics.
Classical software and APIs do the deterministic heavy lifting.
AI acts as the connective tissue: routing, interpreting, drafting, and coordinating.
To stay under the computation ceiling and build systems that execute reliably, implement the following frameworks.
1. Bypass the Ceiling with External Tooling
Do not rely on a language model’s internal “reasoning” to solve complex operational, financial, or technical problems. Treat it as a router and orchestrator.
The agent’s primary job is to recognize patterns: classify requests, understand intents, detect anomalies, and map them to pre-defined actions.
Once the pattern is recognized, the AI calls external, deterministic tools—APIs, databases, spreadsheets, scripts, or SaaS platforms—to perform the actual calculation, update, or transaction.
The AI then interprets the results, formats them for stakeholders, and determines the next step in the workflow based on your rules.
In other words, the AI manages the workflow; your existing software stack enforces the logic and guarantees correctness.
2. Context Engineering Over “Prompting.”
Treat your AI agent like a new hire, not a genie.
You would never hand a brand-new employee every responsibility in the company and say, “Figure it out.” You would:
Clearly define their role and scope.
Give them documented processes.
Train and retrain based on specific mistakes.
Your agents need the same treatment.
Isolate the domain: Build narrow, specialized agents: a Content Agent, a Customer Success Agent, an Outbound Sales Agent, a Billing Agent, etc. Each agent owns one clear swim lane, not the whole ocean.
Strict SOPs, not vague prompts: Replace “be smart and helpful” prompts with 5–10 hard-coded Standard Operating Procedures per agent. For example: “When a lead replies ‘not interested,’ follow Playbook B: log the reason, tag the record, and send Template N.”
Versioned instruction files: When an agent makes a mistake, don’t just tweak a one-off prompt. Update its core instruction file (its “employee manual”), version it, and redeploy. This is how you systematically ratchet performance instead of fighting whack-a-mole.
Context engineering—how you structure roles, rules, and reference material—beats clever prompting every time.
3. Establish a Unified Memory Architecture
Most agentic systems fail slowly, not suddenly. The failure mode is context loss: the agent forgets what happened yesterday, what was promised to the client last week, or what the previous automation already did.
To prevent this, build a unified memory layer:
Centralized “brain”: Connect all agents to a shared database or knowledge index that stores key events, tasks, decisions, and client states.
Mandatory logging: Every time an agent completes a scheduled task, have it write a structured log entry: what it did, for whom, when, and why.
Queryable history: Design your agents to query this shared history before acting—e.g., “Has this client already been sent a follow-up?” or “What was the last ticket status?”
This eliminates “agent amnesia” and keeps your revenue operations aligned, even as different agents handle different lifecycle stages.
4. The Dummy Environment Verification
In a “Sportify” approach to management, nobody steps on the field without surviving practice. The same should apply to your autonomous agents.
Before letting an agent touch production systems:
Build a sandbox: fake email inboxes, duplicate or scrubbed databases, dummy CRM records, test Slack channels, cloned spreadsheets.
Run your scheduled automations end-to-end in this environment. Force the agent to execute its SOPs against realistic but non-critical data.
Establish a promotion threshold: for example, the agent must hit a 95%+ correctness rate across a defined test suite (no broken links, no incorrect statuses, no wrong calculations, no off-brand messaging) before it is allowed to act on live systems.
Even after deployment, keep periodic “scrimmage tests” to ensure updates or model changes haven’t silently degraded performance.
This is how you prevent one misconfigured agent from deleting records, spamming clients, or mispricing offers.
The Bottom Line
The sharpest integrators are not waiting for some mythical artificial general intelligence to descend from the cloud and scale their brand for them. They are exploiting the physics of what already works.
By constraining AI agents to narrow roles, arming them with external tools, grounding them in a unified memory, and holding them to the same gritty, data-driven standards you apply to human teams, you can build an automated workforce that actually performs.
Stop treating AI like magic. Treat it like a system. Architect the environment, enforce the rules, and let the machines do what they are good at—while you stay in charge of the game.
